
Najvažnije SEO greške koje bi mogle upropastiti vašu web stranicu u 2022.
Pročitajte koje su tri najvažnije i najpogubnije SEO pogreške u 2022. godini u novom Konverzijinom blogu
Biste li sjeli za šahovsku ploču, a da ne znate igrati? Čak i da je odgovor pozitivan, sumnjam u uspjeh takvog pothvata. Isto vrijedi i za SEO – ne možete uspjeti ako ne znate kako radi Google. Nakon što pročitate ovaj članak, shvatit ćete kako Google odabire koje će stranice prve prikazati među rezultatima pretrage.
Saznat ćete i kako mu možete pomoći da “presudi” u vašu korist.
Googleov posao počinje pregledavanjem web stranica.
Kako ne postoji središnji registar svih svjetskih web resursa, Google mora redovito analizirati cijeli world wide web. Da bi to učinio, on koristi automatizirani softver poznat kao web crawler ili, jednostavnije, Googlebot.
Googlebot redovito “krstari” internetom u potrazi za novim ili nedavno ažuriranim web stranicama. Taj se proces na engleskom jeziku naziva crawling. U pravilu se to vrši na nekoliko načina.
Prije svega, Googlebot posjećuje stranice koje je već otkrio tijekom prethodnih pregleda. Tada slijedi ili sve poveznice koje se tamo nalaze ili XML kartu web stranice (sitemapu), ukoliko je ona izrađena. Sve novopronađene stranice se zatim dodaju na popis stranica za kasnije indeksiranje.
Googlebot također indeksira stranice koje putem Google Search konzole pošalju vlasnici web stranica. U ovoj konzoli Googlebot zaprima još web stranica, koje dodaje u svoj red čekanja za indeksiranje.
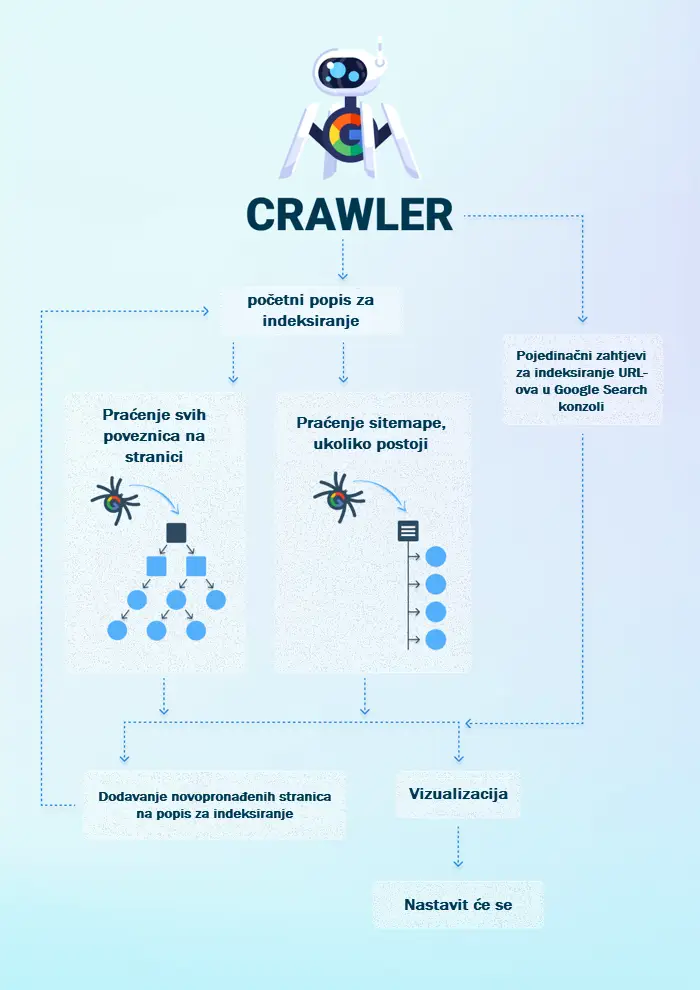
Uobičajeno, Googlebot će indeksirati sve nove stranice koje pronađe. Međutim, stranica neće biti indeksirana ako:
Ako je stranica duplikat druge stranice, Googlebot će je rjeđe posjećivati, kako bi indeksiranje bilo učinkovitije.
Osim pronalaženja novih stranica na webu, faza indeksiranja uključuje i renderiranje (vizualizaciju) novootkrivene stranice. Googlebot koristi preglednik Chrome za učitavanje HTML-a stranice, kodove treće strane, JavaScripta i CSS-a.
Nakon što Googlebot pronađe novu stranicu, pokušava razumjeti o čemu se na njoj radi. Taj je proces poznat kao indeksiranje. Uključuje temeljitu analizu svih elemenata stranice kao što su: tekstualni sadržaj, meta oznake i atributi, slike i video zapisi itd.
U pravilu se sve novootkrivene i indeksirane stranice indeksiraju. Jedina je iznimka ukoliko stranica ima direktivu noindex u oznaci ili zaglavlju. U tom slučaju Googlebot neće indeksirati stranicu.
Kada se indeksiranje završi, alat za indeksiranje katalogizira stranicu u Google indeksu – bazi podataka Google pretraživanja. U ovom momentu Googleov indeks broji na stotine milijardi web stranica.
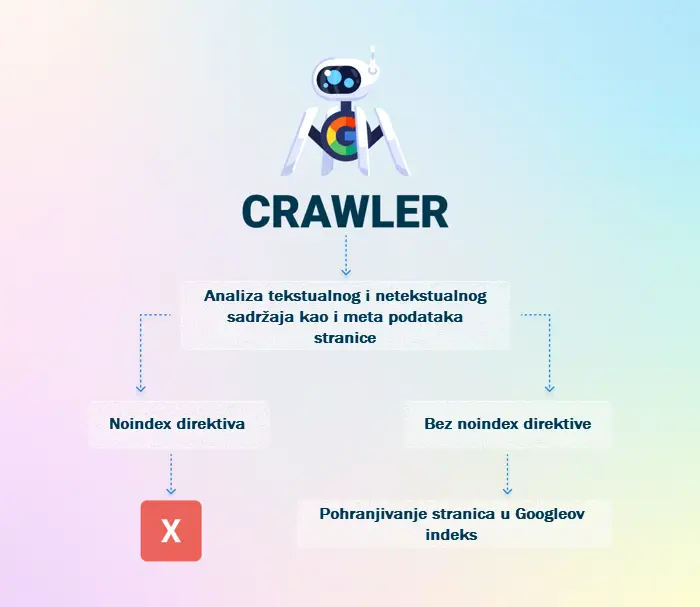
Nakon što se nova stranica indeksira, spremna je za posluživanje pretraživačima.
Svaki put kada korisnik unese upit u okvir za pretraživanje, Google se obraća svojem indeksu kako bi pronašao i poslužio najrelevantnije rezultate. Proces se naziva “posluživanje” i uključuje osam koraka.
U trenutku kada pošaljete svoj zahtjev za pretraživanje, Google će istog momenta uzeti u obzir nekoliko stvari koje će mu pomoći da suzi indeks i filtrira irelevantne rezultate.
Evo što Google provjerava i prije nego što pritisnete tipku Enter:
Nakon što Googleu pošaljete svoj zahtjev za pretraživanje, on mora razumjeti stvarno značenje vašeg upita. Korisnici ne znaju uvijek ispravno sročiti upit.
Prva stvar koju Google čini po tom pitanju je prepoznavanje novih riječi i ispravljanje pravopisnih pogrešaka. Google koristi modele razumijevanja prirodnog jezika za dešifriranje nepoznatih riječi, lapsusnih i konceptualnih pogrešaka. To se uglavnom postiže gledanjem cijelog upita umjesto fokusiranja na jednu riječ.
Zatim Google identificira značenje i namjeru upita. Ranije je Google spajao riječi iz upita s riječima na stranicama bez razumijevanja njihovog značenja. Ovo se promijenilo 2013. godine uvođenjem algoritma Hummingbird. Time je Google zakoračio u novu eru semantičkog pretraživanja i razvio svoje mogućnosti razumijevanja značenja upita umjesto pojedinačnih ključnih riječi. Ovo ažuriranje preteča je sustava umjetne inteligencije koji je postao najveći napredak u prirodnoj obradi jezika.
SEO stručnjaci diljem svijeta pokušavaju otkriti algoritme umjetne inteligencije koje Google koristi, no ta je tema sve samo ne jasna. Možda razlog leži u tome što Google ne želi dijeliti svoje poslovne tajne. Ili možda Googleovi glasnogovornici nisu dovoljno upućeni. U svakom slučaju, najautoritativnije i najjasnije sročeno štivo o ovoj temi je ova objava Barryja Schwartza.
Postoje 3 sustava semantičke obrade na koje Barry stavlja naglasak: RankBrain, Neural Matching i BERT. Pokretani su postupno, a ciljevi im se preklapaju. Njihove sfere utjecaja se – u svrhu pojednostavljavanja – mogu podijeliti kako slijedi:
RankBrain 2015
Spajanje upita s određenim konceptima iz stvarnog svijeta
Primjer: ako pretražujete po upitu “kako se zove konzument na najvišoj razini prehrambenog lanca”, Googleovi sustavi znaju da koncept prehrambenog lanca možda ima veze sa životinjama, a ne s ljudskim konzumentima = potrošačima. Razumijevanjem i spajanjem ovih riječi s njihovim povezanim konceptima, RankBrain pomaže Googleu da shvati da tražite ono što se obično naziva “vršni predator”.
Neural Matching, 2018
Spajanje upita s njihovim sinonimima
Primjer: ako pretražujete pojam “shvaćanje zelenog upravljanja”, Google primjenjuje svoj sustav sinonima kako bi identificirao šira značenja iza riječi (poput upravljanja, vodstva, osobnosti i više) i dešifrirao da tražite savjete za upravljanje na temelju popularnog vodiča za osobnost temeljenog na bojama.
BERT, 2019
Spajanje riječi u upitu s određenim sintaktičkim ulogama
Primjer: ako pretražujete pojam “možete li dobiti lijek za nekoga ljekarna”, BERT pomaže Googleu da shvati da pokušavate otkriti možete li podići lijek za nekoga drugog. Prije BERT-a, Google je taj kratki prijedlog uzimao zdravo za gotovo, uglavnom servirajući rezultate o tome kako ispuniti recept.
Primjenom ova tri algoritma umjetne inteligencije, s dodatkom nekih ne toliko poznatih “čarolija”, Google razumije značenje upita i prelazi na sljedeću fazu.
Nakon što Google shvati značenje i namjeru vašeg upita za pretraživanje, provjerava tražite li nešto što zahtijeva najnovije i najaktualnije informacije (vijesti, politika, događaji itd.)
Kako bi otkrio tražite li aktualne informacije, Google na vaš upit primjenjuje matematički model Query Deserves Freshness (QDF). Ovaj model potvrđuje da je tema “vruća” ukoliko web stranice s vijestima ili postovi na blogovima aktivno objavljuju o tome. Također, ako se jednostavno bilježi povećani opseg pretraživanja o toj temi. Kada Google zaključi da je to tema o kojoj želite dobiti najsvježije informacije, tada nagrađuje ažurni sadržaj višom pozicijom u rezultatima pretrage.
Na primjer, ako u posljednje vrijeme pretražujete “rusija i ukrajina”, vjerojatno očekujete da ćete vidjeti neke vijesti o sukobu dvije zemlje. Dakle, Google prikazuje Top Stories s najnovijim vijestima o ratu na vrhu rezultata pretraživanja:

Uz QDF provjeru, Google analizira vaš upit kako bi vidio je li to onaj za kojega Google smatra neprihvatljivim vraćanje nepouzdanog sadržaja. Takvi upiti i stranice nazivaju se “novac ili život” (NIŽ). U pravilu su to zdravstvene, sigurnosne, financijske i sl. teme.
S tzv. Medic ažuriranjem postalo je moguće prepoznavati “novac ili život” upite i povezati ih s relevantnim sadržajem. Ako Google odluči da upit zahtijeva NIŽ sadržaj, procjenjuje stručnost, autoritativnost i pouzdanost relevantnih stranica, njihovih kreatora i web stranica općenito. Stranice s višom ocjenom tih varijabli, na koncu će biti bolje rangirane.
Primjerice, ukoliko je pojam pretrage “covid”, prva stranica rezultata pretrage (SERP) će se uglavnom sastojati od najpouzdanijih stranica kao što su stranice Svjetske zdravstvene organizacije, Worldometers, državne službene stranice o zarazi i sl.

Ovisno o vrsti upita koji unesete, SERP može izgledati drugačije. Na primjer, uz deset plavih poveznica (organske rezultate pretrage), može prikazati i masu oglasa, rezultate Grafikona znanja, Google kartu i tako dalje.
Dakle, prije nego što Google isporuči konačni SERP, odlučuje koja će vrsta rezultata pretraživanja biti najprikladnija. Kao što pokazuje praksa, SERP struktura uvelike ovisi o namjeri pretraživanja:

Postoji i velika razlika između toga kako radi Google pri odabiru koje značajke SERP-a prikazati pri mobilnom pretraživanju u usporedbi s pretragama na desktop/ laptop računalima.
Primjerice, mobilni SERP posjeduje sljedeće jedinstvene značajke: Proširi ovu pretragu i Pročisti ovu pretragu (prediktivne značajke), Ploču znanja (sa značajkom Gledaj u 3D), Kratke video zapise i Web priče.
Postoje određene značajke koje se češće prikazuju na stolnim računalima, npr. oglasi i istaknuti isječci. Evo primjera kako na različitim uređajima različito može izgledati prvi SERP za identični upit:

Logika iza ove razlike leži u načinu na koji koristimo ove dvije vrste uređaja. Na desktop računalima imamo više vremena za proučavanje tekstualnog sadržaja. Kada koristimo svoje telefone, pak, očekujemo da ćemo informacije pronaći što je brže moguće.
Dakle, Google “oprema” SERP za mobilne uređaje s više prediktivnih i vizualnih značajki.
Nakon što Google shvati koncept pojma pretrage i odredišnih stranica, počinje analizirati koliko kvalitetno informacije na web stranici odgovaraju upitu za pretraživanje.
Kako bi procijenio relevantnost sadržaja, Google analizira tekst, slike i videozapise, kao i sve meta elemente poput naslova, meta opisa i alt oznaka.
Bolje će biti rangirane one stranice koje su relevantnije, odnosno najpotpunije zadovoljavaju zahtjeve korisnika. Ipak, treba zapamtiti da relevantnost sadržaja, iako vitalna, nije jedini čimbenik rangiranja. Kombinacija mnogih čimbenika može maksimizirati šanse za visoke pozicije na SERP-u.
Google rangira stranice dajući prednost najpouzdanijem i najkvalitetnijem sadržaju. Drugim riječima, u ovoj fazi pokušava postići pravu ravnotežu relevantnosti i autoritativnosti informacija.
Prvo što Google u tu svrhu radi je procjena kvalitete sadržaja stranice. Dakle, identificira signale koji pokazuju stručnost, autoritativnost i pouzdanost o određenoj temi. Ovaj proces uključuje:
👊 Procjenu PageRanka. Google provjerava postoje li linkovi s drugih istaknutih web stranica na sadržaj određene stranice, ili upućuju na njega. Broj veza na stranicu je također važan. Što više povratnih veza s drugih kvalitetnih webova stranica dobije, to su joj veće šanse za rangiranje na vrhu.
👊 Otkrivanje bilo kakvog spama ili drugog prijevarnog ili manipulativnog ponašanja zahvaljujući anti-spam algoritmu. Ne treba pretjerano naglašavati; sve što krši Googleove smjernice neće biti visoko rangirano.
👊 Provjera je li stranica sigurna. Google smatra HTTPS zlatnim standardom, jer pruža enkripciju, integritet podataka i autentifikaciju. Ako stranica pruža sigurno korisničko iskustvo, Google će je nagraditi.
Kako je za Google korisničko iskustvo od apsolutno primarne važnosti, također se provjerava i je li stranica jednostavna za navigaciju i korištenje (upotrebljivost stranice). Taj je proces prilično kompliciran i uključuje sljedeće:
⭕ Provjera stranice za nametljive međuprostorne oglase. Ako postoje skočni prozori koji sprječavaju korisnike da konzumiraju glavni sadržaj, stranica neće biti visoko rangirana.
⭕ Provjera je li stranica dizajnirana za sve vrste uređaja. Web sadržaj bi trebao biti podjednako lak za konzumiranje, bilo da se radi o mobitelu, tabletu ili stolnom računalu.
⭕ Uzimanje u obzir temeljne signale web odredišta. Učitavanje, interaktivnost i vizualna stabilnost određuju koliko će vaši posjetitelji biti angažirani i koliko će Google biti dobronamjeran prema vašem sadržaju.
Kao što možemo vidjeti, stranice koje pružaju i kvalitetu i upotrebljivost imaju tendenciju biti bolje rangirane u rezultatima pretraživanja.
Nakon što Google proanalizira vaš upit iz svih kutova, a njegovi algoritmi i umjetna inteligencija odrade svoj posao, Google konačno korisniku poslužuje najrelevantnije rezultate pretrage. Sve što je prikazano na slici ispod traje samo fragment sekunde:

Fun fact #1: Količina vremena koju ste potrošili na čitanje ovog članka do ove točke bila bi dovoljna da Google obradi 38 milijuna upita.
Fun fact #2: Možda mislite da ste upravo shvatili kako radi Google i njegov algoritam. Ali prerano je za slavlje; algoritam se već sutra može izmijeniti 😑
Google ne može ručno mijenjati određene rezultate pretraživanja kako bi poboljšao proces. Umjesto toga, on konstantno mijenja i prilagođava svoje algoritme. Na primjer, samo tijekom 2020. godine Google je u proces pretraživanja uveo oko 4500 poboljšanja. U prosjeku je to oko 12 promjena dnevno. 😯
Neki od važnijih Googleovih poteza u tom smjeru su:
✅ Borba protiv webspama;
✅ Testiranje algoritma;
✅ Najnovija razvojna dostignuća;
Googleov algoritam pretraživanja uvijek će biti obavijen misterijom, koliko god ga globalna SEO zajednica pokušavala razotkriti. Razlog je u tome što Google želi spriječiti bilo kakvu manipulaciju rezultatima pretraživanja od strane trećih strana. Stoga otkriva samo djelić informacija o tome kako algoritam zaista funkcionira.
Nadamo se da Vam je ovaj članak dao neke odgovore i pomogao da shvatite neke osnove o tome kako radi Google i njegov algoritam.
Ako imate pitanja, slodno ih unesite u polje za komentare ispod 👇
Živjeli!
Fotografije: Pixabay
Pročitajte koje su tri najvažnije i najpogubnije SEO pogreške u 2022. godini u novom Konverzijinom blogu

Brzina otvaranja stranice je važan signal za Google. WebP je moderan format slika, koji olakšava sliku bez gubitka na kvaliteti. Saznaj više 👍
Zanima vas koji su to signali koje Google uzima u obzir pri rangiranju stranica u rezultatima pretraga?
2 komentara
👍👏
Hvala na čitanju, Mike 👍